Revisión de Pull Requests
Revisar PRs es un proceso tedioso y consume tiempo
El problema:
• Revisar manualmente cada cambio lleva tiempo• Errores comunes que se repiten
• Contexto difícil de mantener en PRs grandes
Automatizar parte de esto para poder revisarlo antes de que un humano lo vea es bacán, y nos podemos aprovechar de los LLMs para hacerlo
El Verdadero Problema
Para que un agente pueda revisar código necesita:
Entender qué hace cada parte del código
Navegar entre funciones, archivos, módulos
Comprender cómo se relacionan las piezas
Encontrar dependencias y efectos de un cambio
¿Cómo representamos el código para que un agente lo pueda explorar?
Desglosando el Problema
En todo proyecto hay dos relaciones fundamentales:
Jerarquía
La estructura del código
Archivos organizados en directorios
Clases anidadas dentro de otras
Funciones definidas dentro de clases
Referencias
Cómo las partes interactúan
Llamadas a funciones
Asignaciones de variables
Importaciones
Observemos un Código Típico
utils/math.js
export function calculateTotal(items) {
return items.reduce(
(sum, item) => sum + item.price,
0
);
}
export function applyDiscount(total, percent) {
return total * (1 - percent / 100);
}services/order.js
import {
calculateTotal,
applyDiscount
} from '../utils/math';
export function processOrder(cart, discount) {
const subtotal = calculateTotal(cart.items);
const final = applyDiscount(subtotal, discount);
return { subtotal, final };
}controllers/checkout.js
import { processOrder } from '../services/order';
export async function handleCheckout(req, res) {
const result = processOrder(
req.body.cart,
req.user.discountCode
);
await saveTransaction(result);
res.json(result);
}Cada Archivo Tiene una Estructura
Folder: src/
contains ↓
Folder: utils/
contains ↓
File: math.js
defines ↓
Method: calculateTotal()
Method: applyDiscount()
Folder: src/
contains ↓
Folder: services/
contains ↓
File: order.js
defines ↓
Method: processOrder()
Relaciones de contención:
Folder contains Folder o FileFile defines Class o Method
Class defines Method o Class
Esto forma un árbol
Pero También Hay Relaciones Entre Nodos
utils/math.js::calculateTotal()
→
import
→
services/order.js::processOrder()
services/order.js::processOrder()
→
calls
→
utils/math.js::calculateTotal()
services/order.js::processOrder()
→
import
→
controllers/checkout.js
Tipos de relaciones:
import - un módulo importa otrocalls - una función llama a otra
instance - instancia de una clase
Estas relaciones cruzan el árbol
La Representación Completa
El código es un grafo
Nodos: Folder, File, Class, Method
Aristas de jerarquía: contains, defines (forman un árbol)
Aristas de referencias: import, calls, instance (cruzan el árbol)
Navegable: Puedes bajar por la jerarquía o saltar por las referencias
No necesitamos inventar una representación
Solo necesitamos extraer el grafo que ya existe
Solo necesitamos extraer el grafo que ya existe
Entonces, programémoslo
Para extraer la jerarquía, podemos usar Tree-sitter
¿Qué nos da Tree-sitter?
Un syntax tree de un archivo en particular
Código Rust
struct Greeter;
impl Greeter {
fn say_hello(&self) {
println!("Hello!");
}
}
fn main() {
let g = Greeter;
g.say_hello();
}Syntax Tree
source_file [0, 0] - [13, 0]
struct_item [0, 0] - [0, 15]
name: type_identifier [0, 7] - [0, 14]
impl_item [2, 0] - [6, 1]
type: type_identifier [2, 5] - [2, 12]
body: declaration_list [2, 13] - [6, 1]
function_item [3, 4] - [5, 5]
name: identifier [3, 7] - [3, 16]
parameters: parameters [3, 16] - [3, 23]
self_parameter [3, 17] - [3, 22]
body: block [3, 24] - [5, 5]
macro_invocation [4, 8] - [4, 28]
function_item [8, 0] - [11, 1]
name: identifier [8, 3] - [8, 7]
parameters: parameters [8, 7] - [8, 9]
body: block [8, 10] - [11, 1]
let_declaration [9, 4] - [9, 20]
pattern: identifier [9, 8] - [9, 9]
expression_statement [10, 4] - [10, 18]
call_expression [10, 4] - [10, 17]
Tree-sitter es ampliamente usado por editores de código para syntax highlighting
Gramáticas de Tree-sitter
grammar.json (Python)
{
"name": "python",
"rules": {
"module": {
"type": "REPEAT",
"content": {
"type": "SYMBOL",
"name": "_statement"
}
},
"_statement": {
"type": "CHOICE",
"members": [
{
"type": "SYMBOL",
"name": "_simple_statements"
},
{
"type": "SYMBOL",
"name": "_compound_statement"
}
]
},
...
}
Hacer una gramática es un dolor de cabeza
Pero la comunidad ya lo hizo
Oficiales:
C#, Go, Haskell, Java, JavaScript, Kotlin, Python, Rust, Swift, Zig
Third-party:
C++, Crystal, D, Delphi, ELisp, Julia, Lua, OCaml, Perl, PHP, R, Ruby, y más...
Solo necesitas usar la gramática,
no crearla desde cero
no crearla desde cero
El Grafo Resultante
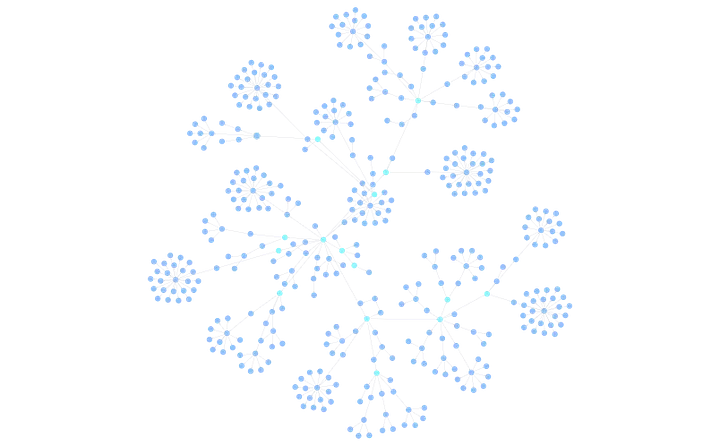
Detalle del Grafo
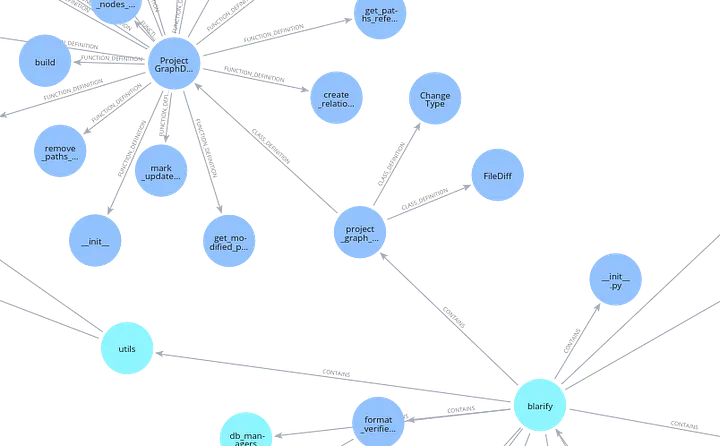
¿Y las Referencias?
Necesitamos encontrar las referencias entre diferentes partes del código: llamadas a funciones, asignaciones de variables, imports
Por suerte, este problema ya está semi-resuelto
Language Server Protocol (LSP)
Podemos colgarnos del mismo protocolo que permite que en un editor de código puedas saltar a definiciones y referencias.
Con LSP podemos extraer referencias sin implementar parsers y analizadores específicos para cada lenguaje
LSP nos da las aristas de referencias del grafo: imports, calls, instances
LSP + Tree-sitter
El problema:
LSP nos dice dónde está la referencia (línea y caracteres), pero no qué tipo de referencia es
La solución:
1. LSP nos da la posición: línea 5, caracteres 10-18
2. Usamos Tree-sitter para encontrar el nodo más pequeño en esa posición
3. Recorremos el AST hacia arriba hasta encontrar un nodo que haga match con un tipo de relación conocido
2. Usamos Tree-sitter para encontrar el nodo más pequeño en esa posición
3. Recorremos el AST hacia arriba hasta encontrar un nodo que haga match con un tipo de relación conocido
Ejemplo:
function_definition
└─ identifier "processOrder" ← LSP apunta aquí
Recorremos hacia arriba y encontramos function_definition
→ Esta referencia es una definición de función
└─ identifier "processOrder" ← LSP apunta aquí
Recorremos hacia arriba y encontramos function_definition
→ Esta referencia es una definición de función
Grafo con LSP
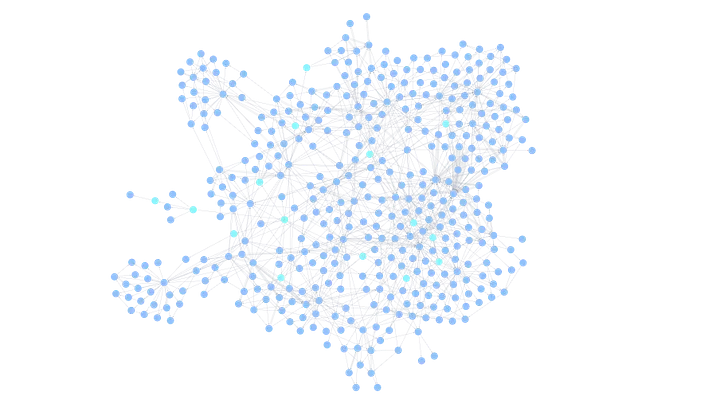
Detalle del Grafo con LSP
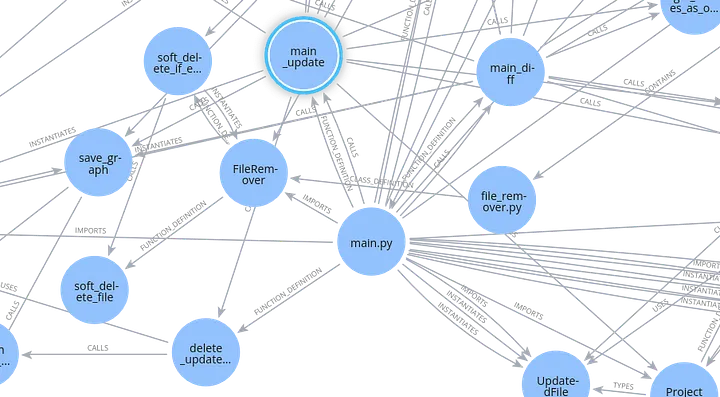
Limitación Importante
Tiempo de Ejecución
Lenguajes como Ruby tienen implementaciones LSP lentas y con features faltantes, haciendo que la generación del grafo demore varios minutos.
Solución
Updates incrementales del grafo
(Da para otra presentación)
Open Source - Licencia MIT
https://github.com/blarApp/blarify